Basic
ES and Relational Database:
Elasticsearch Index == Database
Types == Tables
Properties == Schema
ES Cluster:
1 Node == n shards
Shard == 1 lucene instance, which contains many segments
Segment == mini lucene index, multiple segments can be merged into one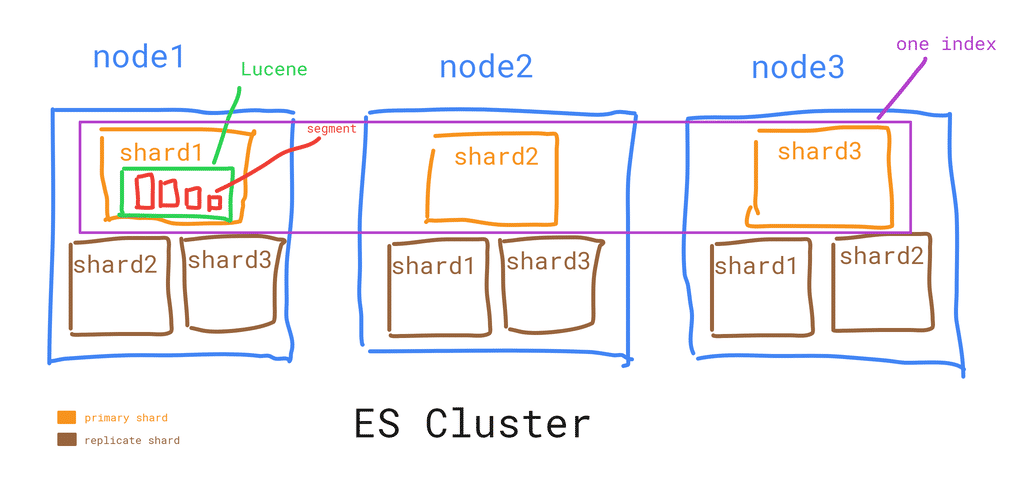
Master Node: maintaining the global state of the cluster.
Data-only Node: hold data and handle CRUD operations on data
Other nodes: coordinating only, etc.
Common Operations
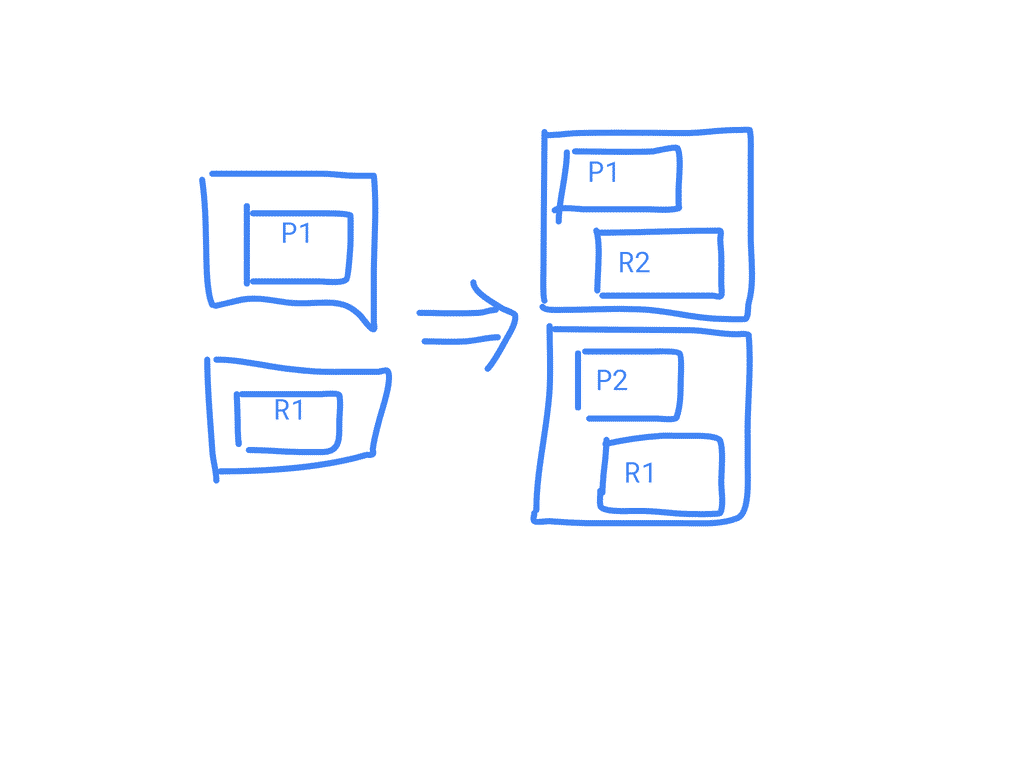
Add an index
Add a doc
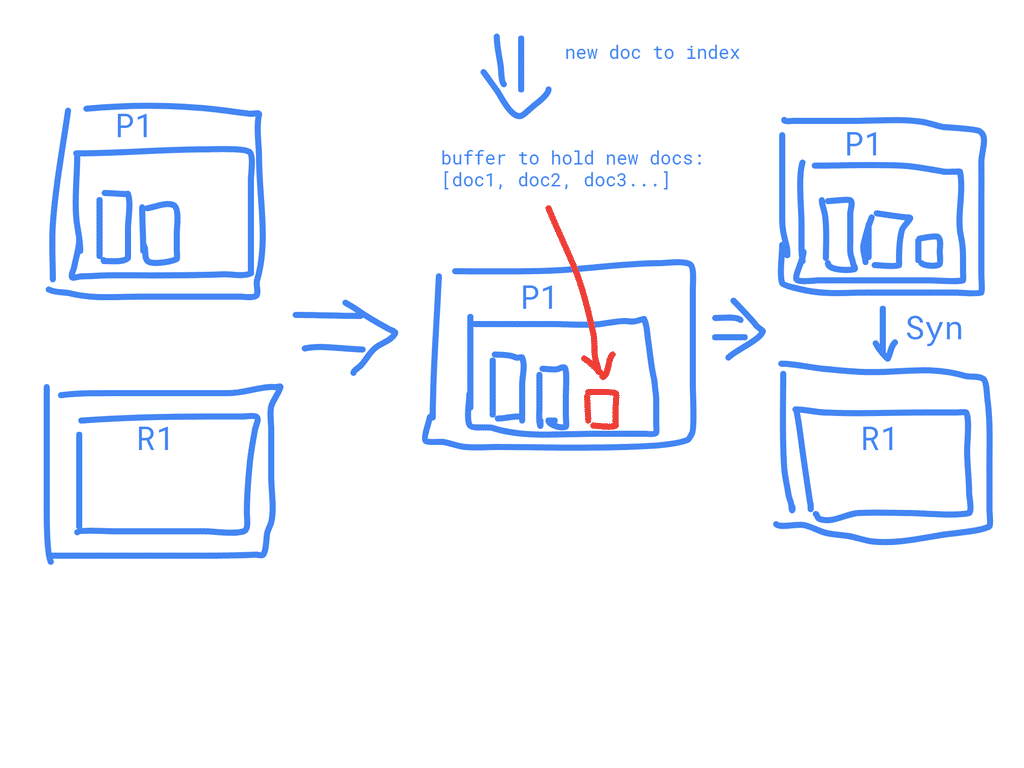
New documents are collected in an in-memory indexing buffer
Every so often, the buffer is commited:
- A new segment—a supplementary inverted index—is written to disk.
- A new commit point is written to disk, which includes the name of the new segment.
- The disk is fsync’ed—all writes waiting in the filesystem cache are flushed to disk, to ensure that they have been physically written.
- The new segment is opened, making the documents it contains visible to search.
- The in-memory buffer is cleared, and is ready to accept new documents.
Query on an index
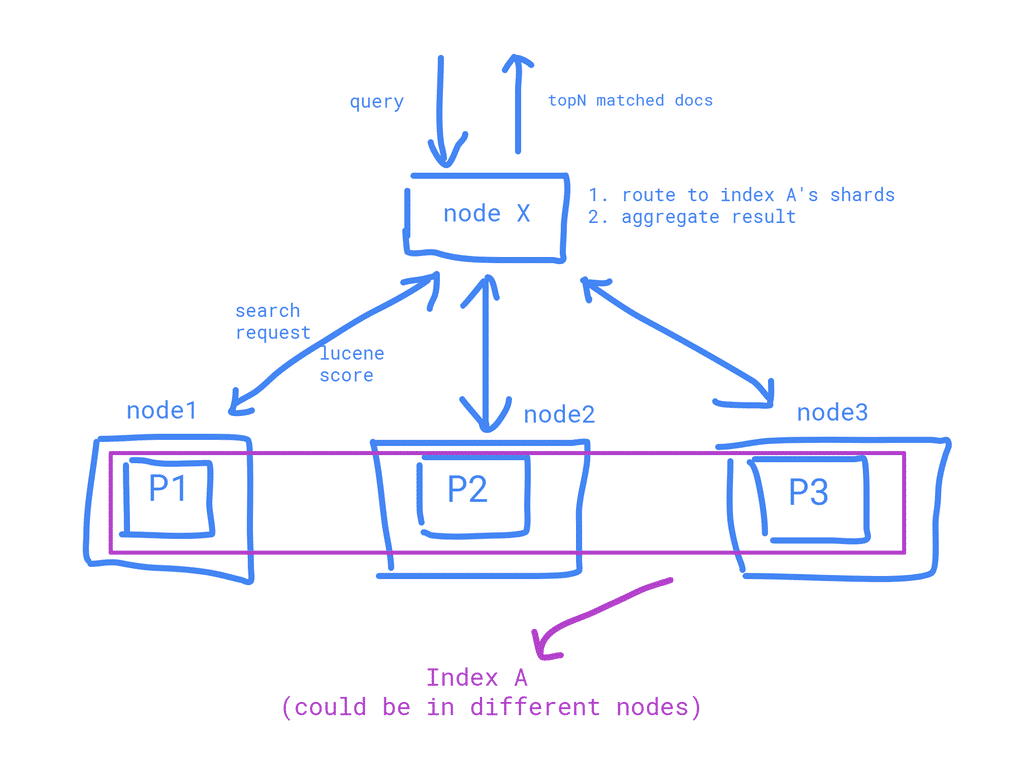
Delete/Update an index/doc
When a document is “deleted,” it is actually just marked as deleted in the .del file. A document that has been marked as deleted can still match a query, but it is removed from the results list before the final query results are returned. Updating is working in a similar way.
Regularly, the deleted doc will be purged after the auto segment mergine process.
Cluster Inside
How to find a shard
When a node gets a query, it will use:shard = hash(routing) % number_of_primary_shards
to find the shard. Routing can be the any string. By default, it is the doc id.
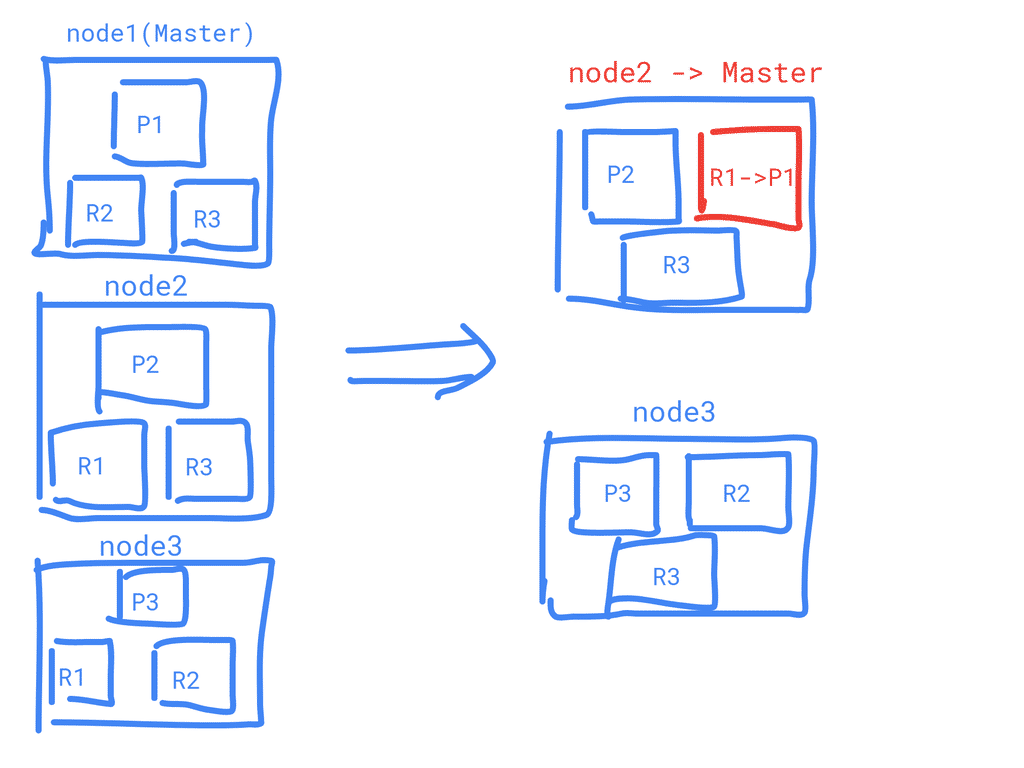
How ES handle failure